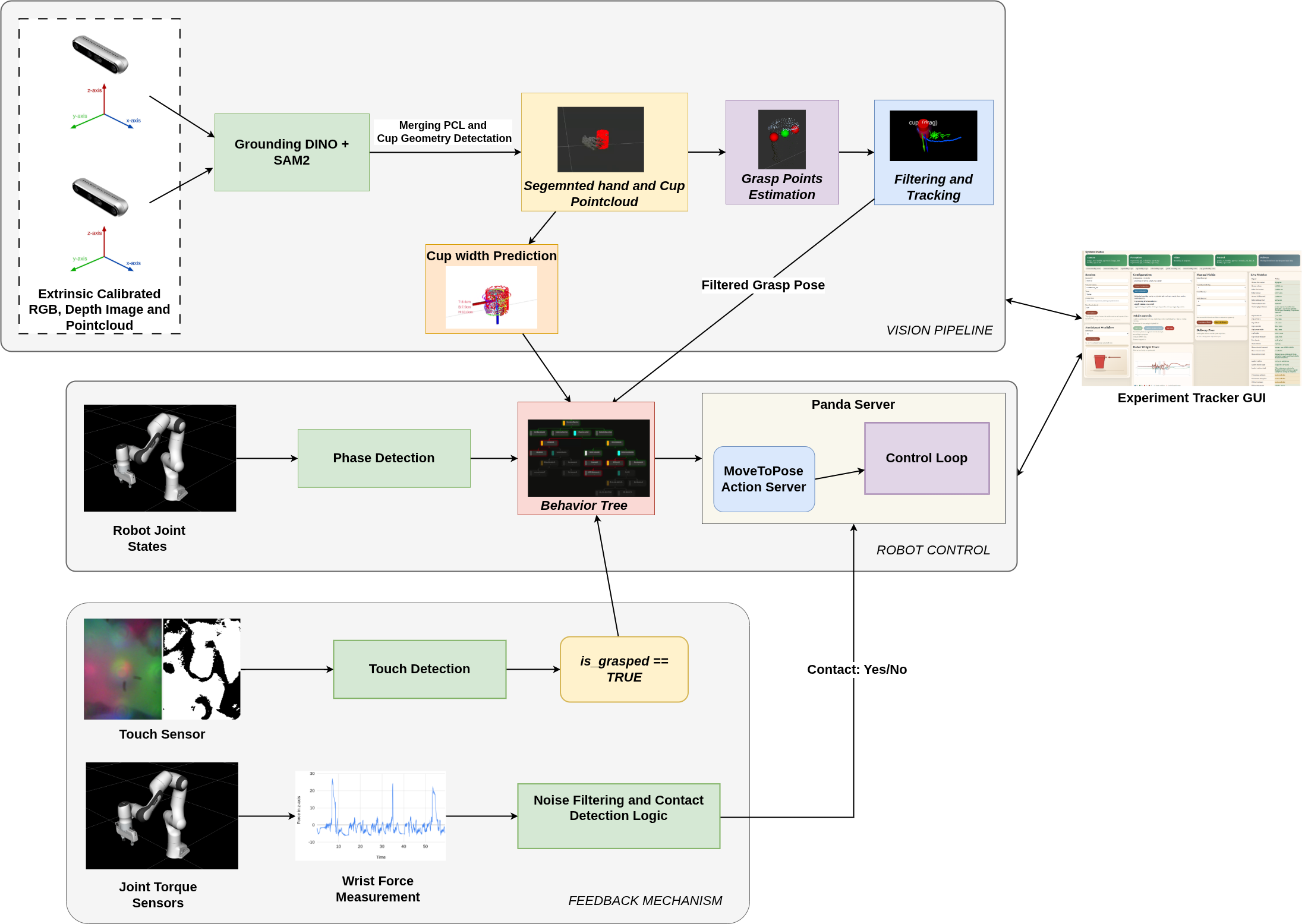
Two extrinsically calibrated Intel RealSense D455 cameras independently segment the container and human hand, estimating 3D positions and velocities. Masks from Grounded-DINO and SAM2 are merged at the tracker level for robust, occlusion-resilient state estimation.
A parametric cylinder model is fitted to the segmented point cloud to estimate the cup's top width, bottom width, height and volume. VLM based geometric reasoning infer the fill level and approximate content mass.
A multi-phase behaviour tree (Initialization → Cup Tracking → Handover & Grasping → Robot Delivery) transitions based on touch sensing and proximity thresholds, ensuring the robot acts only when the human is ready to release.
A grasp classifier selects top, middle, or bottom grasp configurations based on the detected hand-object layout. DIGIT fingertip tactile sensors confirm contact. Velocity control keeps the interaction fast and safety bounderies keep it safe.